


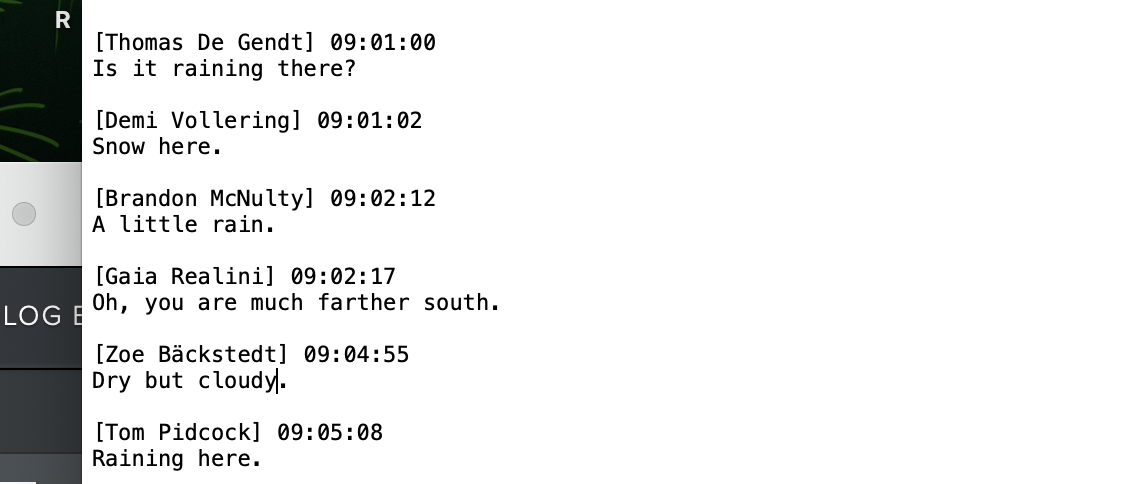
 I have had increasing opportunities in recent years to work with video interview transcripts created by video conferencing software. These come out with a lot of inaccuracy, which I think is best managed by close checking. I find more annoying the amount of clutter - names, time stamps and sentences split across lines when a new time stamp is added every time someone pauses. The sample screenshot above has been altered to substitute a selection of professional cyclists names for real meeting attendees; only in my imagination would I be able to convene this group on a video call to chat about the weather! I cleaned a few of these by hand, which took several hours before starting to explore options. I calculate that having a text file that is moderately inaccurate, probably saves 1/3 to 2/3 of the time when compared to creating a typed transcript from scratch. But the keystrokes to delete metadata - time and names - and move text - keep this from being optimally efficient. Both Zoom and Teams save the transcript or caption files, by default as vtt. If you save captions locally and are not the meeting manager you might end up with .txt, however. If you do have the file as a .vtt, a really fast option it this online .vtt cleaner. The downside of the cleaner is that you end up with no spacing, just a continuous paragraph of text. If your aim is to check this against a recording, however, it will give you a pretty good start, although you cannot see where one speaker ends and the next begins, so adding back in this spacing/formatting may add to the clean up time. I was pretty sure Python was the way to go, and I reached out to statistical consulting at my university. A super helpful consultant provided me with code in the Google Colaboratory. This was pretty nice because it allowed me to run Python without really understanding what I was doing or having to run the program directly itself. Another advantage of the Colaboratory solution was that, subject to naming an organization, I could clean multiple files at once - as many as I put in the designated folder. The first thing done in the Google Colab was to transform the .vtt (which is like a plain text file) into a data frame - once I saw that, it all sort of fell into place for me conceptually. I am interested enough to plan to learn to be at least Python competent, if not proficient, over the summer months. In the end, I identified a far simpler way to pretty much accomplish what I needed. I did a little experimenting with find and replace in Word. First I saved .vtt files as .txt then pasted the text into a Word doc. I could get rid of names, although one at a time, by putting them in find and replacing with a blank or with shorthand - M: for moderator and P: for participant. Since I rarely have more than a dozen participants, this was actually not that bad, I just selected and pasted one after another in the find what box. But the time stamps proved more challenging. I got rid of the hours - 09, 10, for 9 and 10 a.m. respectively - but was not going to put in every possible combination of minutes. Luckily, now that I knew specifically what I wanted to to - remove minutes from Zoom transcript - I found the right find and replace command, shown below, to remove all digits. Since Zoom and Teams rarely produce digits in the transcript itself, this gets rid of just the time stamps, nothing else. My take away, or one of them at least, is that the general search "Clean Zoom transcripts" gave me lots of complicated responses and sample code, but nothing that, in my view, was as fast and easy as this. Part of my preference for this solution has to do with the fact that I plan to listen to the recording anyway because neither Zoom nor Teams is particularly accurate in capturing the correct words used in a video interview. If I was OK with the text of the transcript as produced, the Google Colab option that manages multiple files would be ideal. 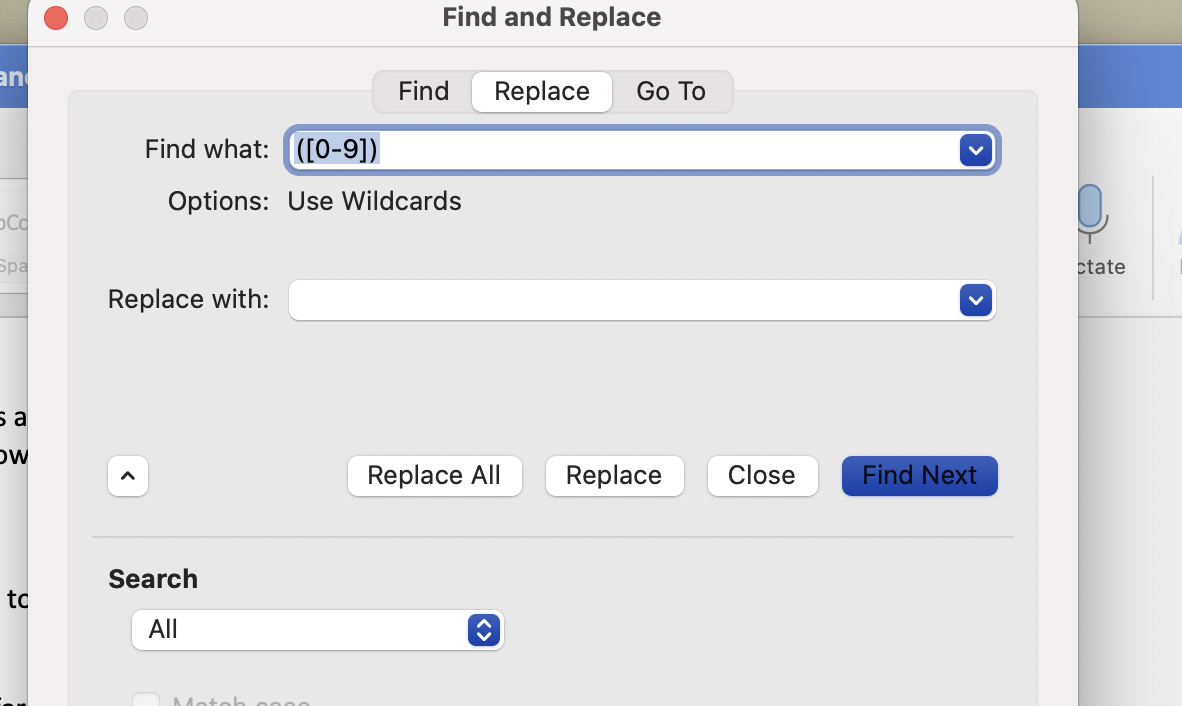
0 Comments
Leave a Reply. |
AuthorI am Sheryl L. Chatfield, Ph.D, C.T.R.S. I am a member of the faculty in the College of Public Health at Kent State University. I also Co-coordinate the Graduate Certificate in Qualitative Research and I am a member of the Design Innovation Team at Kent State. Archives
February 2024
Categories
|
 RSS Feed
RSS Feed