


|
Coherence is a frequently-used term in the guidance for reviewers provided by TQR: The Qualitative Report. As used in this guidance, it refers primarily to alignment among elements. Many people pick a method first. Some pick a question, purpose or area of interest first. In the traditional approach, informed by the scientific method, a careful investigation of the existing body of knowledge reveals fruitful areas for further investigation. Sadly, in a world where the number of published research articles is increasing steadily (not to mention pre-prints, that I have very mixed, leaning toward negative, opinions on) the ability to develop solid knowledge of the state of any area of research is increasingly a challenge.  I see a couple of frequent strategies used by authors or researchers in response to the overabundance of information.
1 Comment
The cliché I used for my title is one of those things that is floating around in my head without any specific reference or example. The prototypical scenario involves someone who has acquired or is considering, a work of modern art or other non-traditional creative endeavor - dance, music, etc. - and is generally someone who is both wealthy and has poor taste. In an alternate or comparative scenario, the person has already acquired some stereotypical representation of "low brow" culture - like a velvet Elvis picture, or print of dogs playing poker - and this phrase is offered in defense of their selection.
I started thinking about this when I was looking at checklists to assess qualitative research, which I was doing yesterday when I looked at potential journals for submitting a qualitative research report for publication. This particular report leans toward health science - versus social science or health behavior or methods - which are the other areas I typically focus on. Health science and related areas like healthcare research - are the types of areas in my experience where it is more common to encounter checklist requirements. The Lancet, for example, requires authors to use a standard checklist for any submitted research report. I am not against research checklists in general - and they definitely have utility in meta-studies where the quality of integrated results depends on quality of source articles - but I find some of the specific items concerning I've long been aware of and interested in the informal way people communicate research guidance. A great many of the informal standards also begin with "You must," "Always...", "Never...", and other absolutes although there are some that incorporate dichotomous guidance ("You must always do either X or Y..." 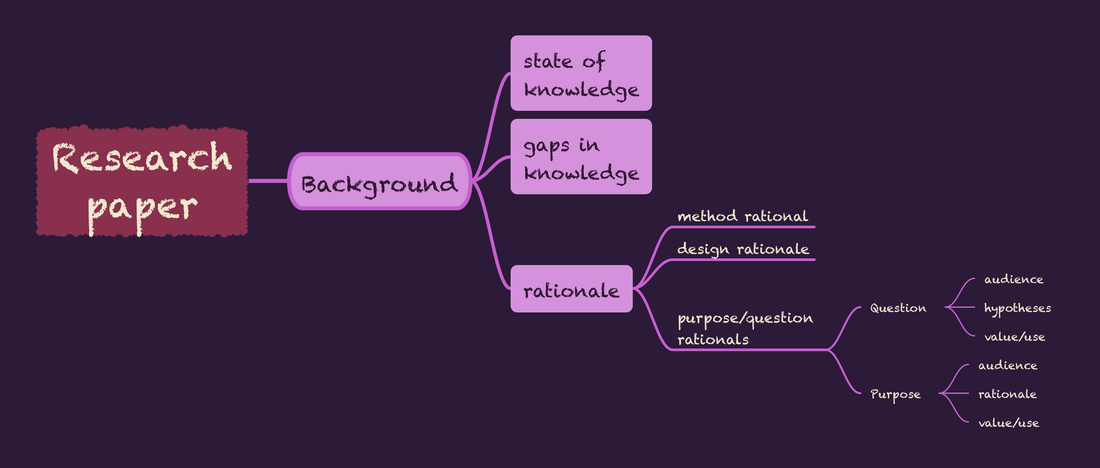 I encountered a somewhat serendipitous example this week - "serendipitous" because one of the co-authors offered one of these rules while we were writing - while a peer reviewer offered the opposing view. Specifically the co-author shared guidance provided by their graduate mentor that the discussion section of a paper could only consider/re-consider the research described in the introductory or background (AKA initial review of literature) section.
In contrast, included in a list of reviewer criticisms was some of the same papers were described in both the introduction and the discussion. So, which is right? Clearly not both. My ownresponse is "neither. I believe both of these guidelines are arbitrary and do not take into account the aims of the particular sections of a research article.   I was just looking at the Sage Methodspace, https://www.methodspace.com/for something unrelated to this blog, and I signed up for their newsletter because the current topic of focus - matching purpose to design - is something I'm especially interested in.
Also note I still cannot get links to work properly here, so the link follows rather than being aligned with the text. As I signed up, I was given a choice of roles. I selected "higher education," (see upper photograph) which I think most precisely describes what I do and where I do it, although I admit - one alternative option "further education" (see the lower picture) was a lot more appealing.  I modeled my first efforts at peer review on peer review responses I had previously seen. I suspect this is how most people learn.
Later I had dedicated instruction during a qualitative methods course offered at Nova Southeastern University. I also obtained some great resources including this paper (LINK) and the reviewer guide provided by the online journal TQR: The Qualitative Report. One of the things I have long been curious about is the way reviewers address authors. TQR's ready reviewer comments are typically written like a dialogue with the authors, e.g., "I suggest you consider...." although there are also probably some phrased more like "I suggest the authors consider...." - this is more formal but still feels like there is an information exchange. The style I saw more frequently as a new reviewer used phrasing to make it sound (look) as if the reviewer was speaking to someone else (editor, presumably) about the author and their work. I'm not referring to the "confidential comments to editor" space provided by a lot of journal but instead to the peer review comments themselves. In writing, reviewing, and editing, I find myself continually considering and commenting about words and voice or tone. I tend to write complex and run on sentences and my awareness of this may make me more attuned to it in the work of others. Also, as my confidence in my own knowledge has increased, I am more likely to make comments when things do not make sense to me, rather than assuming authors know what they are talking (writing) about.
I'll be honest and say 2023 was not a great year and this is evidenced by very low activity in this blog, although by that measure 2021 was not very good either. I'm happy to say farewell to 2023 and entering 2024 with some enthusiasm, which will no doubt increase when the weather warms up! I'm planning something different for this blog during this year - instead of blogging about things that strike me as interesting, I hope to devote most of the space to posts about words, language, and precision. Unfortunately some of my peers consider language use, and maybe writing in general, as bothersome tasks to be delegated to (subordinate - students or junior faculty) others. I do not believe this is because their competence is so great that they can afford to pass along practice opportunities to others. Somewhere in something I read the author Ray Bradbury suggested writers should write daily, and I think that is excellent advice for writers of any type, at any level. But over and over again I've heard things like "we don't have time for wordsmithing," "we'll clean up the details later," or even with regard to style and formatting "that is for the copyeditor to deal with." These things all to me suggest that the actual act of putting words on paper is not highly valued by all. In contrast I tend to think, with regard to research, an article written for publication is probably the most important output, most of the time. But if it is hard to understand, poorly organized, unclear, includes errors, even is tedious or boring, the consumption and appreciation potential of the work declines. On the other hand, I will, and have happily read things outside of my interest area (or use) that were engagingly written. I'm following this introductory post with one about peer reviewing and hopefully that sets the tone for a productive blog in 2024. The title of this post is a lyric from the song "Words" written by Terry Bozzio and Warren Cuccurullo and recorded by the band they were in at the time Missing Persons. The rest of that line is: "What are words for when no one listens anymore?" I cannot get the usual link process to work so the link to the song is below. www.youtube.com/watch?v=IasCZL072fQ  Is there still value in the review of literature as a type of (secondary) research paper? I think the answer is "it depends." I wrote a mildly ranting post for a research interest group last week about reviews of literature and have been thinking about this since that time. I also collaborated on a scoping review earlier this year and have recently been having discussions with a doctoral candidate about the potential structure of a research review component of a three manuscript dissertation. Previously I worked with some students and faculty members on a couple of never completely finished (to the point of being submitted for publication) systematic reviews. My only actual authorship of a published review was a qualitative meta-study, which is a less often used variation within research reviews.
This is probably an average level of experience but I have a sense that, relative to my peers, I have above average skepticism about reviews of literature. It feels like I change the theme about once a decade or so, and it felt like time. I have not had a photo on this and now I do. Other image #1: zinnia from my backyard - these come out late and last a long time. They are still blooming now. Other image #2: laser cut wood patterns from the KSU Design Innovation Hub. I did not make those and do not know who did, so I cannot give credit. This is one of many examples of maker things on display in the DI Hub reactor room.
aWidespread availability of and interest in AI models (e.g., ChatGPT) has not surprisingly motivated more researchers and/or people who need to demonstrate research activity to try to figure out new ways to report findings based on minimal direct engagement with data.
During the Golden Age of QDAS (Qualitative Data Analysis Software) emergence - by which I mean some point in the 2010s when NVivo, Atlas.ti, MAXQDA, and to a lesser extent the pioneer in web-based QDAS, Dedoose, were becoming known and more widely used, it seemed that a lot of people around me were particularly excited about the potential to use a qualitative analog of statistical software programs like SPSS or SAS. By this, I mean a mechanism for entering or directing toward your data, clicking some boxes and obtaining comprehensive output that showed the final analysis. Of course the QDAS programs did not quite work like that and were instead database builders were text was selected instead of typed, and categories could be created as you went, rather than needing to create the organizational structure beforehand. This to me was still great progress, especially in these programs' ability to run queries and hyperlink to context of each coded excerpt. I have coded in Word a lot, and still use Word. But it requires work arounds to see context and is not ideal for people who do not have great typing skills. And although I did not mention Quirkos above - because it came along a little later than the others, it is my go to QDAS program these days. These programs have all become more sophisticated over time. However, even the so-called auto coding (or theory building, available in HyperRESEARCH) functions are mostly researcher initiated, and require some prompts, and cannot interpret context although the program may identify patterns, typically based on frequency. Because, in a way, you could think of most analysis software - qualitative or quantitative, as a sort of calculator. The same thing applies to the things people used to talk about, like machine learning algorithms, before "artificial intelligence," which is admittedly a much sexier term, became so popular. As an aside, I wonder how many people visualize "artificial intelligence" as female? I'm thinking about many references through time including the original "Star Trek" computer voice, Siri and Alexa, OnStar, the 1970s "Stepford Wives," the 1929 Metropolis movie poster, Rosie from "The Jetsons," and Scarlett Johansson in "Her." Of course there are some discomforting cases, the "Lost in Space" robot, and Kit, the car from "Knight Rider." I am personally curious right now how often already ChatGPT and competitors have been asked to analyze qualitative data. 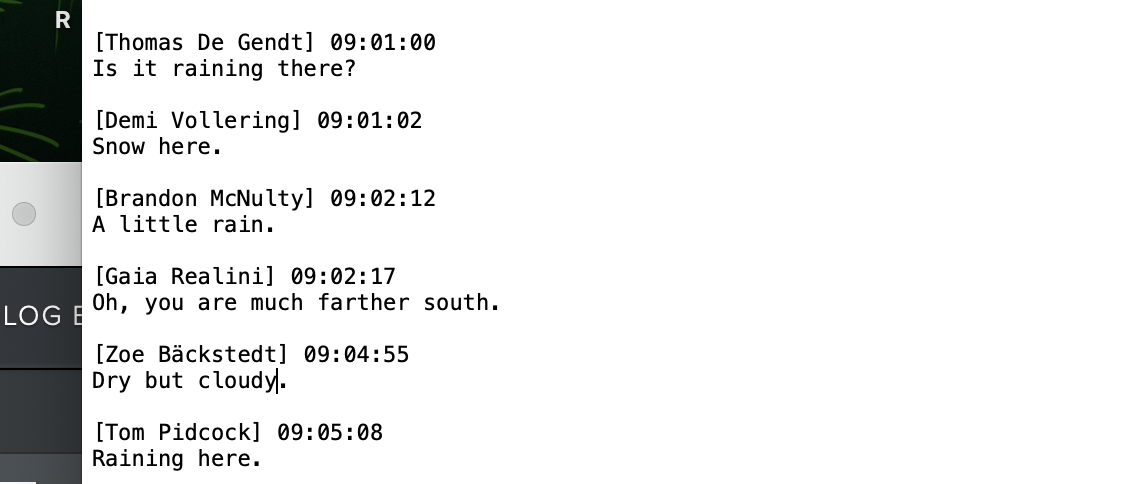 I have had increasing opportunities in recent years to work with video interview transcripts created by video conferencing software. These come out with a lot of inaccuracy, which I think is best managed by close checking. I find more annoying the amount of clutter - names, time stamps and sentences split across lines when a new time stamp is added every time someone pauses.
The sample screenshot above has been altered to substitute a selection of professional cyclists names for real meeting attendees; only in my imagination would I be able to convene this group on a video call to chat about the weather! I cleaned a few of these by hand, which took several hours before starting to explore options. I calculate that having a text file that is moderately inaccurate, probably saves 1/3 to 2/3 of the time when compared to creating a typed transcript from scratch. But the keystrokes to delete metadata - time and names - and move text - keep this from being optimally efficient. Both Zoom and Teams save the transcript or caption files, by default as vtt. If you save captions locally and are not the meeting manager you might end up with .txt, however. If you do have the file as a .vtt, a really fast option it this online .vtt cleaner. The downside of the cleaner is that you end up with no spacing, just a continuous paragraph of text. If your aim is to check this against a recording, however, it will give you a pretty good start, although you cannot see where one speaker ends and the next begins, so adding back in this spacing/formatting may add to the clean up time. I was pretty sure Python was the way to go, and I reached out to statistical consulting at my university. A super helpful consultant provided me with code in the Google Colaboratory. This was pretty nice because it allowed me to run Python without really understanding what I was doing or having to run the program directly itself. Another advantage of the Colaboratory solution was that, subject to naming an organization, I could clean multiple files at once - as many as I put in the designated folder. The first thing done in the Google Colab was to transform the .vtt (which is like a plain text file) into a data frame - once I saw that, it all sort of fell into place for me conceptually. I am interested enough to plan to learn to be at least Python competent, if not proficient, over the summer months. In the end, I identified a far simpler way to pretty much accomplish what I needed. |
AuthorI am Sheryl L. Chatfield, Ph.D, C.T.R.S. I am a member of the faculty in the College of Public Health at Kent State University. I also Co-coordinate the Graduate Certificate in Qualitative Research and I am a member of the Design Innovation Team at Kent State. Archives
February 2024
Categories
|
 RSS Feed
RSS Feed